Lab Streaming Layer (LSL) do synchronizacji wielu strumieni danych
Roshini Randeniya i Lucas Kleine
Zaktualizowano dnia
2 maj 2024
Lab Streaming Layer (LSL) do synchronizacji wielu strumieni danych
Roshini Randeniya i Lucas Kleine
Zaktualizowano dnia
2 maj 2024
Lab Streaming Layer (LSL) do synchronizacji wielu strumieni danych
Roshini Randeniya i Lucas Kleine
Zaktualizowano dnia
2 maj 2024
przez Roshini Randeniya i Lucas Kleine
Operacja:
Po uruchomieniu w wierszu poleceń ten skrypt natychmiast inicjuje strumień LSL. Kiedykolwiek naciśnięty zostanie klawisz 'Enter', wysyła wyzwalacz i odtwarza plik audio."""
importuj sounddevice jako sd
importuj soundfile jako sf
z pylsl importuj StreamInfo, StreamOutlet
definicja wait_for_keypress():
print("Naciśnij ENTER, aby rozpocząć odtwarzanie dźwięku i wysłać znacznik LSL.")
while True: # This loop waits for a keyboard input input_str = input() # Wait for input from the terminal if input_str == "": # If the enter key is pressed, proceed break
definicja AudioMarker(audio_file, outlet): # funkcja do odtwarzania dźwięku i wysyłania znacznika
dane, fs = sf.read(audio_file) # Ładowanie pliku audio
print("Playing audio and sending LSL marker...") marker_val = [1] outlet.push_sample(marker_val) # Send marker indicating the start of audio playback sd.play(data, fs) # play the audio sd.wait() # Wait until audio is done playing print("Audio playback finished.")
jeśli nazwa == "main": # GŁÓWNA PĘTLA
# Konfiguracja strumienia LSL dla znaczników
nazwa_strumienia = 'AudioMarkers'
typ_strumienia = 'Markers'
n_chans = 1
sr = 0 # Ustaw na 0 częstotliwość próbkowania, ponieważ znaczniki są nieregularne
chan_format = 'int32'
marker_id = 'uniqueMarkerID12345'
info = StreamInfo(stream_name, stream_type, n_chans, sr, chan_format, marker_id) outlet = StreamOutlet(info) # create LSL outlet # Keep the script running and wait for ENTER key to play audio and send marker while True: wait_for_keypress() audio_filepath = "/path/to/your/audio_file.wav" # replace with correct path to your audio file AudioMarker(audio_filepath, outlet) # After playing audio and sending a marker, the script goes back to waiting for the next keypress</code></pre><p><em><strong>**By running this file (even before playing the audio), you've initiated an LSL stream through an outlet</strong></em><strong>. Now we'll view that stream in LabRecorder</strong></p><p><strong>STEP 5 - Use LabRecorder to view and save all LSL streams</strong></p><ol><li data-preset-tag="p"><p>Open LabRecorder</p></li><li data-preset-tag="p"><p>Press <em><strong>Update</strong></em>. The available LSL streams should be visible in the stream list<br> • You should be able to see streams from both EmotivPROs (usually called "EmotivDataStream") and the marker stream (called "AudioMarkers")</p></li><li data-preset-tag="p"><p>Click <em><strong>Browse</strong></em> to select a location to store data (and set other parameters)</p></li><li data-preset-tag="p"><p>Select all streams and press <em><strong>Record</strong></em> to start recording</p></li><li data-preset-tag="p"><p>Click Stop when you want to end the recording</p></li></ol><p><br></p><img alt="" src="https://framerusercontent.com/images/HFGuJF9ErVu2Jxrgtqt11tl0No.jpg"><h2><strong>Working with the data</strong></h2><p><strong>LabRecorder outputs an XDF file (Extensible Data Format) that contains data from all the streams. XDF files are structured into, </strong><em><strong>streams</strong></em><strong>, each with a different </strong><em><strong>header</strong></em><strong> that describes what it contains (device name, data type, sampling rate, channels, and more). You can use the below codeblock to open your XDF file and display some basic information.</strong></p><pre data-language="JSX"><code>
**Uruchomienie tego pliku (nawet przed odtwarzaniem audio) powoduje zainicjowanie strumienia LSL przez outlet. Teraz zobaczymy ten strumień w LabRecorder
KROK 5 - Użyj LabRecorder, aby zobaczyć i zapisać wszystkie strumienie LSL
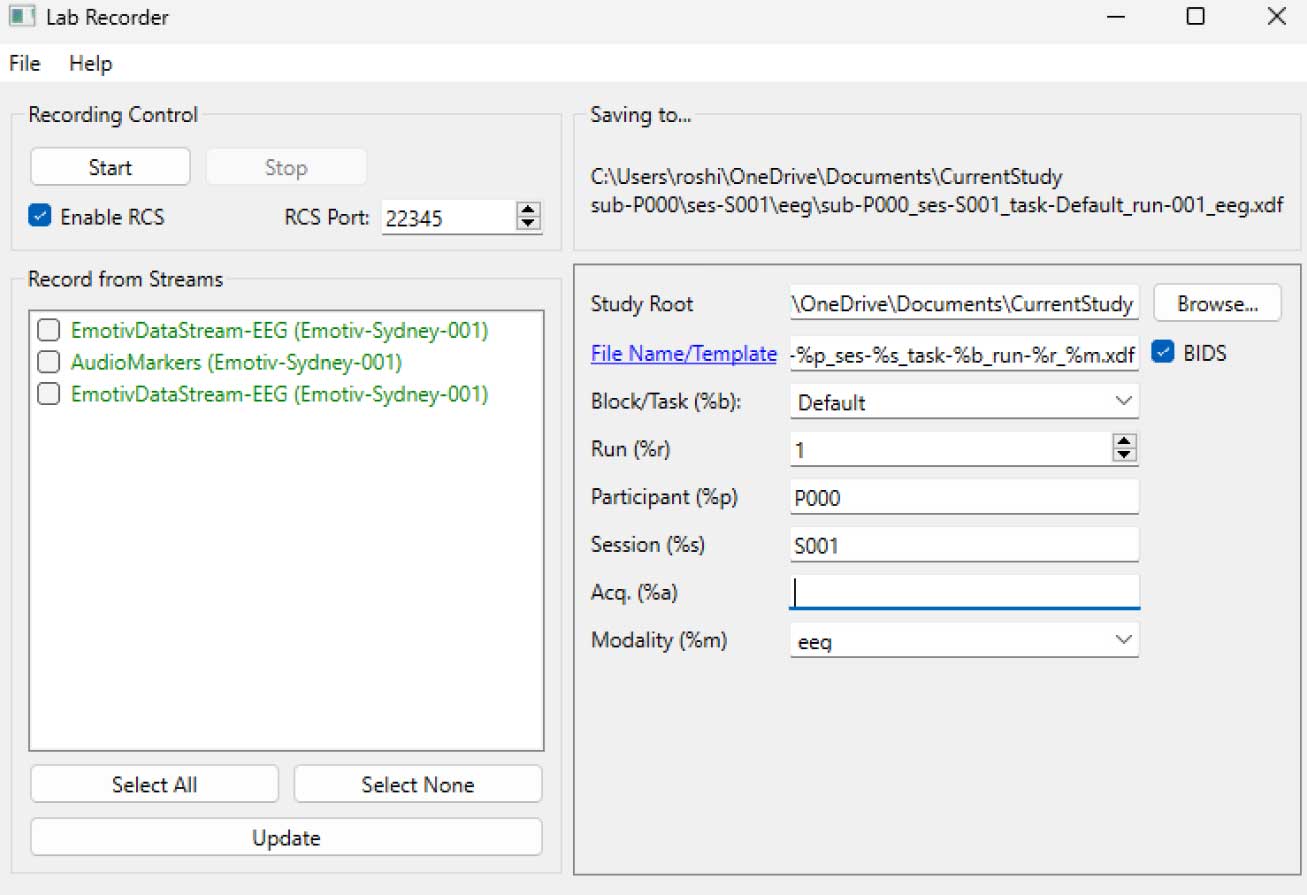
Otwórz LabRecorder
Naciśnij Aktualizuj. Dostępne strumienie LSL powinny być widoczne na liście strumieni
• Powinieneś móc zobaczyć strumienie zarówno z EmotivPROs (zwykle nazywane "EmotivDataStream"), jak i strumień znaczników (nazywany "AudioMarkers")Kliknij Przeglądaj, aby wybrać miejsce do przechowywania danych (i ustawić inne parametry)
Wybierz wszystkie strumienie i naciśnij Nagrywaj aby rozpocząć nagrywanie
Kliknij Stop, gdy chcesz zakończyć nagrywanie
Praca z danymi
LabRecorder wyjściem jest plik XDF (Extensible Data Format), który zawiera dane ze wszystkich strumieni. Pliki XDF są zorganizowane w,strumienie, z każdym posiadającym innynagłówekopisujący, co zawiera (nazwa urządzenia, typ danych, częstotliwość próbkowania, kanały i więcej). Możesz użyć poniższego fragmentu kodu, aby otworzyć plik XDF i wyświetlić kilka podstawowych informacji.
Ten przykładowy skrypt demonstruje kilka podstawowych funkcji importu i adnotacji danych EEG zebranych za pomocą oprogramowania EmotivPRO. Używa MNE do ładowania pliku XDF, drukowania niektórych podstawowych metadanych, tworzenia obiektu info i przedstawienia widma mocy."""
importuj pyxdf
importuj mne
importuj matplotlib.pyplot jako plt
importuj numpy jako np
Ścieżka do twojego pliku XDF
ścieżka_danych = '/path/to/your/xdf_file.xdf'
Załaduj plik XDF
strumienie, nagłówek_pliku = pyxdf.load_xdf(ścieżka_danych)
print("Nagłówek pliku XDF:", nagłówek_pliku)
print("Ilość znalezionych strumieni:", len(strumienie))
dla i, strumień w enumerate(strumienie):
print("\nStrumień", i + 1)
print("Nazwa strumienia:", strumień['info']['name'][0])
print("Typ strumienia:", strumień['info']['type'][0])
print("Liczba kanałów:", strumień['info']['channel_count'][0])
sfreq = float(strumień['info']['nominal_srate'][0])
print("Częstotliwość próbkowania:", sfreq)
print("Ilość próbek:", len(strumień['time_series']))
print("Wyświetl pierwsze 5 punktów danych:", strumień['time_series'][:5])
channel_names = [chan['label'][0] for chan in stream['info']['desc'][0]['channels'][0]['channel']] print("Channel Names:", channel_names) channel_types = 'eeg'
Stwórz obiekt info MNE
info = mne.create_info(nazwy_kanałów, sfreq, typy_kanałów)
dane = np.array(strumień['time_series']).T # Dane muszą być transponowane: kanały x próbki
raw = mne.io.RawArray(dane, info)
raw.plot_psd(fmax=50) # wyświetla prosty spektrogram (gęstość mocy widmowej)Dodatkowe zasobyPobierz ten poradnik jako notatnik Jupyter z Emotiv GitHubSprawdź internetową dokumentację LSL, w tym oficjalny plik README na GitHubBędziesz potrzebować jednego lub więcej obsługiwanych urządzeń do akwizycji danych do zbierania danychWszystkie urządzenia do monitorowania mózgu EMOTIV łączą się z oprogramowaniem EmotivPRO, które ma wbudowane możliwości LSL do wysyłania i odbierania strumieni danychDodatkowe zasoby:Kod do uruchamiania LSL za pomocą urządzeń Emotiv, z przykładowymi skryptamiPrzydatne demo LSL na YouTubeRepozytorium SCCN LSL GitHub dla wszystkich powiązanych bibliotekRepozytorium GitHub dla kolekcji submodułów i aplikacjiPipeline analizy HyPyP dla badań nad skanowaniem mózgów"
przez Roshini Randeniya i Lucas Kleine
Operacja:
Po uruchomieniu w wierszu poleceń ten skrypt natychmiast inicjuje strumień LSL. Kiedykolwiek naciśnięty zostanie klawisz 'Enter', wysyła wyzwalacz i odtwarza plik audio."""
importuj sounddevice jako sd
importuj soundfile jako sf
z pylsl importuj StreamInfo, StreamOutlet
definicja wait_for_keypress():
print("Naciśnij ENTER, aby rozpocząć odtwarzanie dźwięku i wysłać znacznik LSL.")
while True: # This loop waits for a keyboard input input_str = input() # Wait for input from the terminal if input_str == "": # If the enter key is pressed, proceed break
definicja AudioMarker(audio_file, outlet): # funkcja do odtwarzania dźwięku i wysyłania znacznika
dane, fs = sf.read(audio_file) # Ładowanie pliku audio
print("Playing audio and sending LSL marker...") marker_val = [1] outlet.push_sample(marker_val) # Send marker indicating the start of audio playback sd.play(data, fs) # play the audio sd.wait() # Wait until audio is done playing print("Audio playback finished.")
jeśli nazwa == "main": # GŁÓWNA PĘTLA
# Konfiguracja strumienia LSL dla znaczników
nazwa_strumienia = 'AudioMarkers'
typ_strumienia = 'Markers'
n_chans = 1
sr = 0 # Ustaw na 0 częstotliwość próbkowania, ponieważ znaczniki są nieregularne
chan_format = 'int32'
marker_id = 'uniqueMarkerID12345'
info = StreamInfo(stream_name, stream_type, n_chans, sr, chan_format, marker_id) outlet = StreamOutlet(info) # create LSL outlet # Keep the script running and wait for ENTER key to play audio and send marker while True: wait_for_keypress() audio_filepath = "/path/to/your/audio_file.wav" # replace with correct path to your audio file AudioMarker(audio_filepath, outlet) # After playing audio and sending a marker, the script goes back to waiting for the next keypress</code></pre><p><em><strong>**By running this file (even before playing the audio), you've initiated an LSL stream through an outlet</strong></em><strong>. Now we'll view that stream in LabRecorder</strong></p><p><strong>STEP 5 - Use LabRecorder to view and save all LSL streams</strong></p><ol><li data-preset-tag="p"><p>Open LabRecorder</p></li><li data-preset-tag="p"><p>Press <em><strong>Update</strong></em>. The available LSL streams should be visible in the stream list<br> • You should be able to see streams from both EmotivPROs (usually called "EmotivDataStream") and the marker stream (called "AudioMarkers")</p></li><li data-preset-tag="p"><p>Click <em><strong>Browse</strong></em> to select a location to store data (and set other parameters)</p></li><li data-preset-tag="p"><p>Select all streams and press <em><strong>Record</strong></em> to start recording</p></li><li data-preset-tag="p"><p>Click Stop when you want to end the recording</p></li></ol><p><br></p><img alt="" src="https://framerusercontent.com/images/HFGuJF9ErVu2Jxrgtqt11tl0No.jpg"><h2><strong>Working with the data</strong></h2><p><strong>LabRecorder outputs an XDF file (Extensible Data Format) that contains data from all the streams. XDF files are structured into, </strong><em><strong>streams</strong></em><strong>, each with a different </strong><em><strong>header</strong></em><strong> that describes what it contains (device name, data type, sampling rate, channels, and more). You can use the below codeblock to open your XDF file and display some basic information.</strong></p><pre data-language="JSX"><code>
**Uruchomienie tego pliku (nawet przed odtwarzaniem audio) powoduje zainicjowanie strumienia LSL przez outlet. Teraz zobaczymy ten strumień w LabRecorder
KROK 5 - Użyj LabRecorder, aby zobaczyć i zapisać wszystkie strumienie LSL
Otwórz LabRecorder
Naciśnij Aktualizuj. Dostępne strumienie LSL powinny być widoczne na liście strumieni
• Powinieneś móc zobaczyć strumienie zarówno z EmotivPROs (zwykle nazywane "EmotivDataStream"), jak i strumień znaczników (nazywany "AudioMarkers")Kliknij Przeglądaj, aby wybrać miejsce do przechowywania danych (i ustawić inne parametry)
Wybierz wszystkie strumienie i naciśnij Nagrywaj aby rozpocząć nagrywanie
Kliknij Stop, gdy chcesz zakończyć nagrywanie
Praca z danymi
LabRecorder wyjściem jest plik XDF (Extensible Data Format), który zawiera dane ze wszystkich strumieni. Pliki XDF są zorganizowane w,strumienie, z każdym posiadającym innynagłówekopisujący, co zawiera (nazwa urządzenia, typ danych, częstotliwość próbkowania, kanały i więcej). Możesz użyć poniższego fragmentu kodu, aby otworzyć plik XDF i wyświetlić kilka podstawowych informacji.
Ten przykładowy skrypt demonstruje kilka podstawowych funkcji importu i adnotacji danych EEG zebranych za pomocą oprogramowania EmotivPRO. Używa MNE do ładowania pliku XDF, drukowania niektórych podstawowych metadanych, tworzenia obiektu info i przedstawienia widma mocy."""
importuj pyxdf
importuj mne
importuj matplotlib.pyplot jako plt
importuj numpy jako np
Ścieżka do twojego pliku XDF
ścieżka_danych = '/path/to/your/xdf_file.xdf'
Załaduj plik XDF
strumienie, nagłówek_pliku = pyxdf.load_xdf(ścieżka_danych)
print("Nagłówek pliku XDF:", nagłówek_pliku)
print("Ilość znalezionych strumieni:", len(strumienie))
dla i, strumień w enumerate(strumienie):
print("\nStrumień", i + 1)
print("Nazwa strumienia:", strumień['info']['name'][0])
print("Typ strumienia:", strumień['info']['type'][0])
print("Liczba kanałów:", strumień['info']['channel_count'][0])
sfreq = float(strumień['info']['nominal_srate'][0])
print("Częstotliwość próbkowania:", sfreq)
print("Ilość próbek:", len(strumień['time_series']))
print("Wyświetl pierwsze 5 punktów danych:", strumień['time_series'][:5])
channel_names = [chan['label'][0] for chan in stream['info']['desc'][0]['channels'][0]['channel']] print("Channel Names:", channel_names) channel_types = 'eeg'
Stwórz obiekt info MNE
info = mne.create_info(nazwy_kanałów, sfreq, typy_kanałów)
dane = np.array(strumień['time_series']).T # Dane muszą być transponowane: kanały x próbki
raw = mne.io.RawArray(dane, info)
raw.plot_psd(fmax=50) # wyświetla prosty spektrogram (gęstość mocy widmowej)Dodatkowe zasobyPobierz ten poradnik jako notatnik Jupyter z Emotiv GitHubSprawdź internetową dokumentację LSL, w tym oficjalny plik README na GitHubBędziesz potrzebować jednego lub więcej obsługiwanych urządzeń do akwizycji danych do zbierania danychWszystkie urządzenia do monitorowania mózgu EMOTIV łączą się z oprogramowaniem EmotivPRO, które ma wbudowane możliwości LSL do wysyłania i odbierania strumieni danychDodatkowe zasoby:Kod do uruchamiania LSL za pomocą urządzeń Emotiv, z przykładowymi skryptamiPrzydatne demo LSL na YouTubeRepozytorium SCCN LSL GitHub dla wszystkich powiązanych bibliotekRepozytorium GitHub dla kolekcji submodułów i aplikacjiPipeline analizy HyPyP dla badań nad skanowaniem mózgów"
przez Roshini Randeniya i Lucas Kleine
Operacja:
Po uruchomieniu w wierszu poleceń ten skrypt natychmiast inicjuje strumień LSL. Kiedykolwiek naciśnięty zostanie klawisz 'Enter', wysyła wyzwalacz i odtwarza plik audio."""
importuj sounddevice jako sd
importuj soundfile jako sf
z pylsl importuj StreamInfo, StreamOutlet
definicja wait_for_keypress():
print("Naciśnij ENTER, aby rozpocząć odtwarzanie dźwięku i wysłać znacznik LSL.")
while True: # This loop waits for a keyboard input input_str = input() # Wait for input from the terminal if input_str == "": # If the enter key is pressed, proceed break
definicja AudioMarker(audio_file, outlet): # funkcja do odtwarzania dźwięku i wysyłania znacznika
dane, fs = sf.read(audio_file) # Ładowanie pliku audio
print("Playing audio and sending LSL marker...") marker_val = [1] outlet.push_sample(marker_val) # Send marker indicating the start of audio playback sd.play(data, fs) # play the audio sd.wait() # Wait until audio is done playing print("Audio playback finished.")
jeśli nazwa == "main": # GŁÓWNA PĘTLA
# Konfiguracja strumienia LSL dla znaczników
nazwa_strumienia = 'AudioMarkers'
typ_strumienia = 'Markers'
n_chans = 1
sr = 0 # Ustaw na 0 częstotliwość próbkowania, ponieważ znaczniki są nieregularne
chan_format = 'int32'
marker_id = 'uniqueMarkerID12345'
info = StreamInfo(stream_name, stream_type, n_chans, sr, chan_format, marker_id) outlet = StreamOutlet(info) # create LSL outlet # Keep the script running and wait for ENTER key to play audio and send marker while True: wait_for_keypress() audio_filepath = "/path/to/your/audio_file.wav" # replace with correct path to your audio file AudioMarker(audio_filepath, outlet) # After playing audio and sending a marker, the script goes back to waiting for the next keypress</code></pre><p><em><strong>**By running this file (even before playing the audio), you've initiated an LSL stream through an outlet</strong></em><strong>. Now we'll view that stream in LabRecorder</strong></p><p><strong>STEP 5 - Use LabRecorder to view and save all LSL streams</strong></p><ol><li data-preset-tag="p"><p>Open LabRecorder</p></li><li data-preset-tag="p"><p>Press <em><strong>Update</strong></em>. The available LSL streams should be visible in the stream list<br> • You should be able to see streams from both EmotivPROs (usually called "EmotivDataStream") and the marker stream (called "AudioMarkers")</p></li><li data-preset-tag="p"><p>Click <em><strong>Browse</strong></em> to select a location to store data (and set other parameters)</p></li><li data-preset-tag="p"><p>Select all streams and press <em><strong>Record</strong></em> to start recording</p></li><li data-preset-tag="p"><p>Click Stop when you want to end the recording</p></li></ol><p><br></p><img alt="" src="https://framerusercontent.com/images/HFGuJF9ErVu2Jxrgtqt11tl0No.jpg"><h2><strong>Working with the data</strong></h2><p><strong>LabRecorder outputs an XDF file (Extensible Data Format) that contains data from all the streams. XDF files are structured into, </strong><em><strong>streams</strong></em><strong>, each with a different </strong><em><strong>header</strong></em><strong> that describes what it contains (device name, data type, sampling rate, channels, and more). You can use the below codeblock to open your XDF file and display some basic information.</strong></p><pre data-language="JSX"><code>
**Uruchomienie tego pliku (nawet przed odtwarzaniem audio) powoduje zainicjowanie strumienia LSL przez outlet. Teraz zobaczymy ten strumień w LabRecorder
KROK 5 - Użyj LabRecorder, aby zobaczyć i zapisać wszystkie strumienie LSL
Otwórz LabRecorder
Naciśnij Aktualizuj. Dostępne strumienie LSL powinny być widoczne na liście strumieni
• Powinieneś móc zobaczyć strumienie zarówno z EmotivPROs (zwykle nazywane "EmotivDataStream"), jak i strumień znaczników (nazywany "AudioMarkers")Kliknij Przeglądaj, aby wybrać miejsce do przechowywania danych (i ustawić inne parametry)
Wybierz wszystkie strumienie i naciśnij Nagrywaj aby rozpocząć nagrywanie
Kliknij Stop, gdy chcesz zakończyć nagrywanie
Praca z danymi
LabRecorder wyjściem jest plik XDF (Extensible Data Format), który zawiera dane ze wszystkich strumieni. Pliki XDF są zorganizowane w,strumienie, z każdym posiadającym innynagłówekopisujący, co zawiera (nazwa urządzenia, typ danych, częstotliwość próbkowania, kanały i więcej). Możesz użyć poniższego fragmentu kodu, aby otworzyć plik XDF i wyświetlić kilka podstawowych informacji.
Ten przykładowy skrypt demonstruje kilka podstawowych funkcji importu i adnotacji danych EEG zebranych za pomocą oprogramowania EmotivPRO. Używa MNE do ładowania pliku XDF, drukowania niektórych podstawowych metadanych, tworzenia obiektu info i przedstawienia widma mocy."""
importuj pyxdf
importuj mne
importuj matplotlib.pyplot jako plt
importuj numpy jako np
Ścieżka do twojego pliku XDF
ścieżka_danych = '/path/to/your/xdf_file.xdf'
Załaduj plik XDF
strumienie, nagłówek_pliku = pyxdf.load_xdf(ścieżka_danych)
print("Nagłówek pliku XDF:", nagłówek_pliku)
print("Ilość znalezionych strumieni:", len(strumienie))
dla i, strumień w enumerate(strumienie):
print("\nStrumień", i + 1)
print("Nazwa strumienia:", strumień['info']['name'][0])
print("Typ strumienia:", strumień['info']['type'][0])
print("Liczba kanałów:", strumień['info']['channel_count'][0])
sfreq = float(strumień['info']['nominal_srate'][0])
print("Częstotliwość próbkowania:", sfreq)
print("Ilość próbek:", len(strumień['time_series']))
print("Wyświetl pierwsze 5 punktów danych:", strumień['time_series'][:5])
channel_names = [chan['label'][0] for chan in stream['info']['desc'][0]['channels'][0]['channel']] print("Channel Names:", channel_names) channel_types = 'eeg'
Stwórz obiekt info MNE
info = mne.create_info(nazwy_kanałów, sfreq, typy_kanałów)
dane = np.array(strumień['time_series']).T # Dane muszą być transponowane: kanały x próbki
raw = mne.io.RawArray(dane, info)
raw.plot_psd(fmax=50) # wyświetla prosty spektrogram (gęstość mocy widmowej)Dodatkowe zasobyPobierz ten poradnik jako notatnik Jupyter z Emotiv GitHubSprawdź internetową dokumentację LSL, w tym oficjalny plik README na GitHubBędziesz potrzebować jednego lub więcej obsługiwanych urządzeń do akwizycji danych do zbierania danychWszystkie urządzenia do monitorowania mózgu EMOTIV łączą się z oprogramowaniem EmotivPRO, które ma wbudowane możliwości LSL do wysyłania i odbierania strumieni danychDodatkowe zasoby:Kod do uruchamiania LSL za pomocą urządzeń Emotiv, z przykładowymi skryptamiPrzydatne demo LSL na YouTubeRepozytorium SCCN LSL GitHub dla wszystkich powiązanych bibliotekRepozytorium GitHub dla kolekcji submodułów i aplikacjiPipeline analizy HyPyP dla badań nad skanowaniem mózgów"