Lab Streaming Layer (LSL) pour la synchronisation de flux de données multiples
Dr Roshini Randeniya et Lucas Kleine
Mis à jour le
17 mai 2024
Lab Streaming Layer (LSL) pour la synchronisation de flux de données multiples
Dr Roshini Randeniya et Lucas Kleine
Mis à jour le
17 mai 2024
Lab Streaming Layer (LSL) pour la synchronisation de flux de données multiples
Dr Roshini Randeniya et Lucas Kleine
Mis à jour le
17 mai 2024
Bienvenue ! Dans ce tutoriel, nous allons apprendre à utiliser Lab Streaming Layer (LSL) en Python pour collecter et synchroniser les données EEG d'Emotiv à partir de plusieurs appareils. Cela nécessitera des connaissances de base en langage de programmation Python.
Ce que vous allez apprendre
Ce qu'est Lab Streaming Layer (LSL) et pourquoi les chercheurs l'utilisent
Comment collecter des données synchronisées à partir de plusieurs appareils EEG d'Emotiv
Comment importer et inspecter les données collectées
1.1 Qu'est-ce que LSL et à quoi ça sert ?
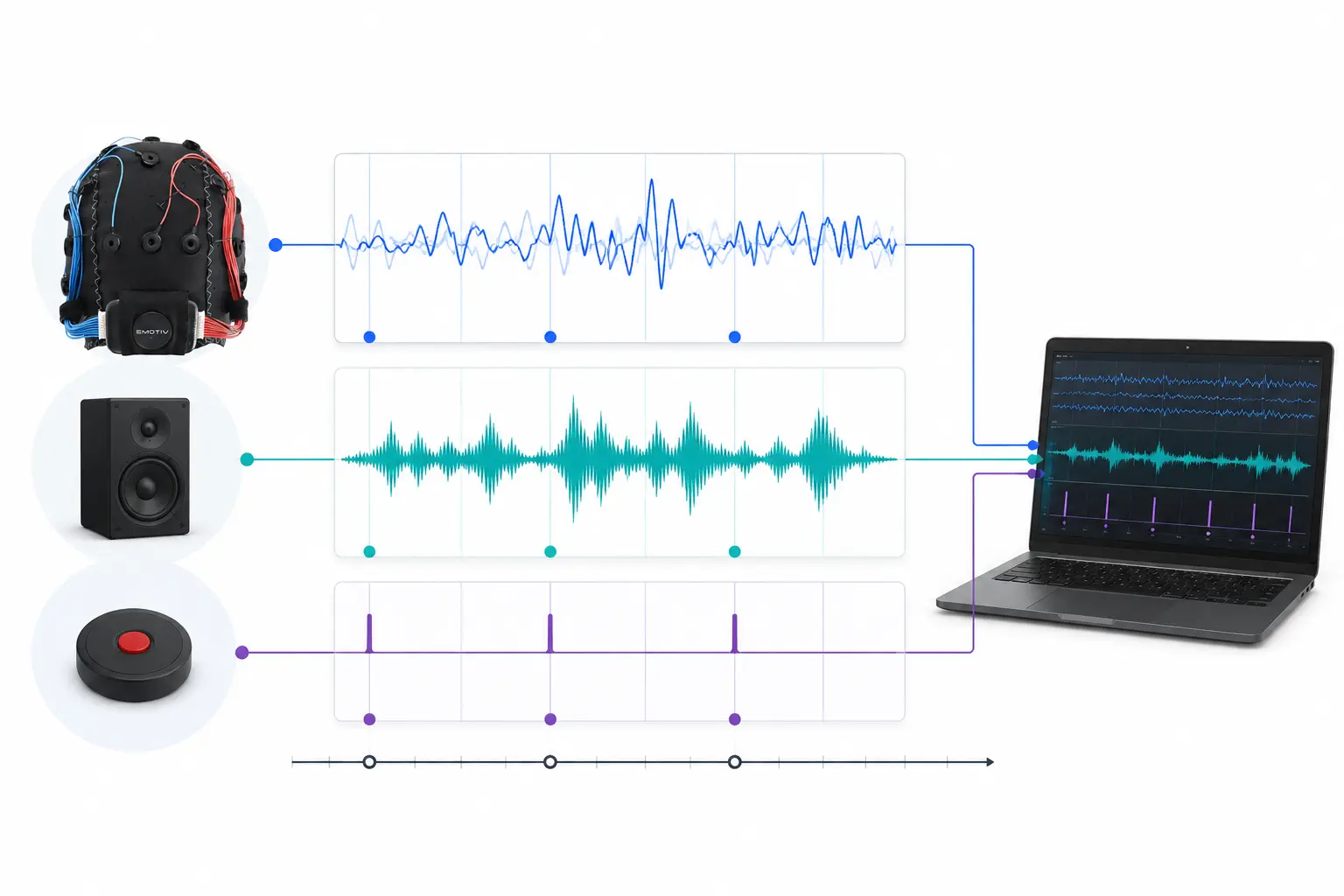
Lab Streaming Layer (LSL) est une boîte à outils open-source qui peut être utilisée pour envoyer, recevoir et synchroniser des flux de données neuronales, physiologiques et comportementales provenant de divers matériels de capteurs. Des appareils de détection cérébrale et corporelle de plus en plus performants, précis et mobiles (comme les systèmes EEG d'Emotiv) amènent les neurosciences hors du laboratoire vers le monde des données en temps réel. Alors que les mesures cérébrales telles que l'EEG et la MEG étaient autrefois confinées aux laboratoires de recherche, les appareils mobiles nous permettent de collecter plusieurs données dans des environnements plus naturalistes, et de plusieurs personnes à la fois.
Un chercheur peut s'intéresser à la synchronie physiologique entre deux personnes écoutant la même musique. LSL peut nous aider à collecter séparément des données de deux casques EEG qui sont également synchronisées avec la présentation du son.
Quelques exemples d'autres utilisations de LSL :
Ajouter des marqueurs d'événements d'une expérience à des données EEG en cours
Aligner temporellement les données de sources multiples pour un seul participant (par exemple, fréquence cardiaque, EMG, EEG)
Aligner temporellement les données de plusieurs participants (par exemple, études d'hyperscan EEG)
1.2 Comment fonctionne LSL ?
Lab Streaming Layer est un protocole d'échange en temps réel de données de séries temporelles entre plusieurs appareils. LSL peut être implémenté à l'aide de bibliothèques open-source pour des langages de programmation tels que Python, MATLAB, C++, Java et autres.
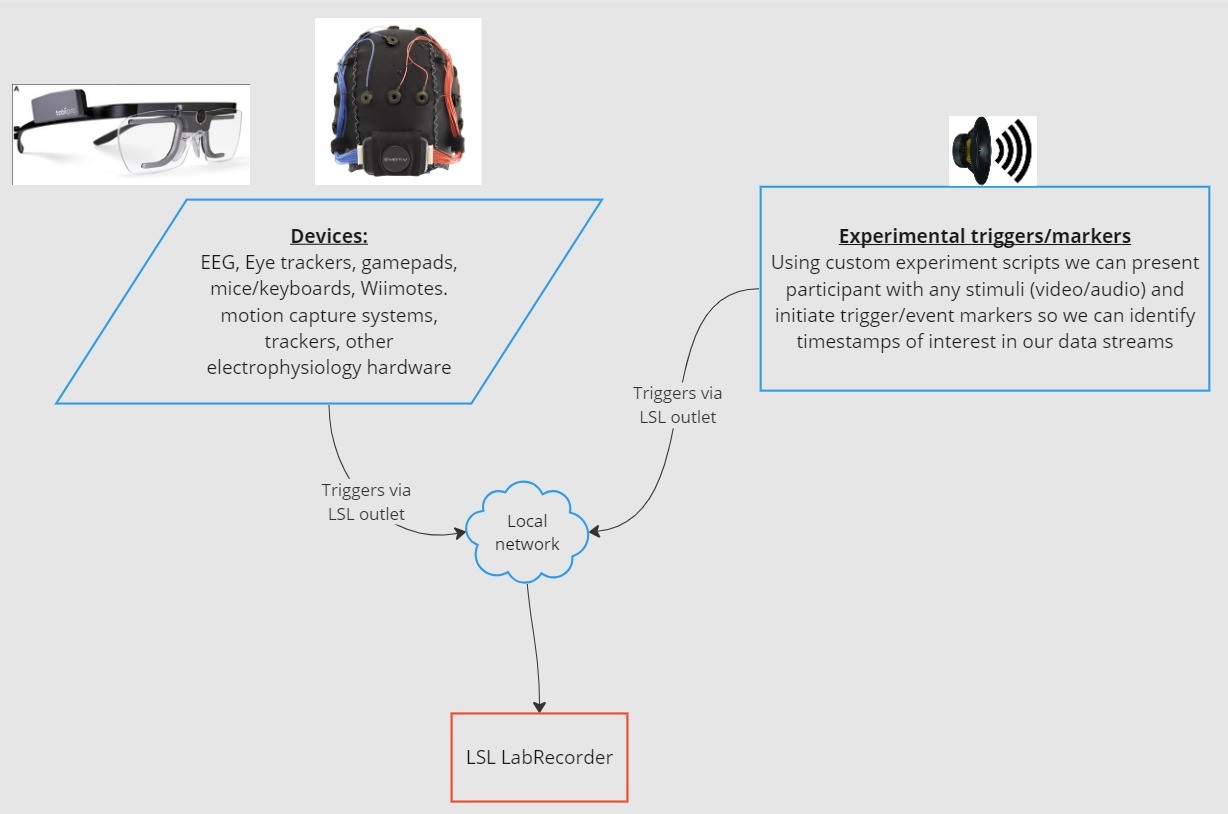
La fonctionnalité principale tourne autour des flux de données LSL :
1. Un appareil/logiciel d'acquisition collecte les données et crée un flux de données - Les données physiologiques peuvent être transmises à LSL à partir d'appareils d'enregistrement EEG, d'oculomètres, de systèmes de capture de mouvement, de moniteurs de fréquence cardiaque, etc., y compris les métadonnées (taux d'échantillonnage, type de données, informations sur les canaux, etc.) - Les marqueurs d'événements issus d'expériences (par exemple, en utilisant PsychoPy) peuvent également être envoyés sous forme de flux de données à l'aide de LSL
2. Le flux de données est publié sur le réseau - C'est ainsi que les données sont envoyées à l'aide de LSL ; le flux de données est « diffusé » sur le réseau - Les flux publiés sont disponibles sur le réseau et détectables par d'autres appareils compatibles LSL sur le même réseau - LSL attribue à chaque bloc de données ou échantillon un horodatage basé sur une horloge commune (suivant le protocole Network Time Protocol). - Le flux est poussé échantillon par échantillon (ou bloc par bloc) à travers une « sortie » (outlet)
3. Les appareils de collecte s'« abonnent » aux flux de données - C'est ainsi que les données sont reçues à l'aide de LSL - Les appareils de collecte sur le même réseau reçoivent les flux de données publiés via des « entrées » (inlets). - Chaque entrée reçoit les échantillons de flux et les métadonnées d'une seule sortie
4. Sauvegarder les données - Lors de l'abonnement à un flux de données, vous pouvez le sauvegarder dans une variable de votre langage de programmation préféré, ou utiliser le logiciel fourni par LSL, LabRecorder, pour le sauvegarder dans un format standard tel que .xdf.
2.0 Aperçu du tutoriel
Dans ce tutoriel, nous prendrons un exemple d'installation expérimentale et vous guiderons à travers les étapes et le code nécessaires pour l'implémenter en utilisant LSL en Python. Nous utiliserons Python pour jouer un son tout en collectant des données EEG de deux personnes portant des casques Emotiv. Nous utiliserons deux ordinateurs exécutant chacun EmotivPRO pour collecter les données EEG, et diffuser chaque flux par une sortie LSL distincte. Nous utiliserons une bibliothèque Python pour lire un fichier audio et envoyer simultanément un déclencheur à chaque fois que le fichier démarre.
ÉTAPES :
1. Utiliser EmotivPRO pour diffuser des données via des sorties LSL qui incluent des données EEG (et/ou mouvement, qualité de contact, qualité du signal, etc.) 2. Lire une piste audio à l'aide d'un script Python, et envoyer simultanément un déclencheur via une autre sortie LSL. Utiliser LabRecorder pour capturer et sauvegarder les trois flux de données via une entrée LSL.
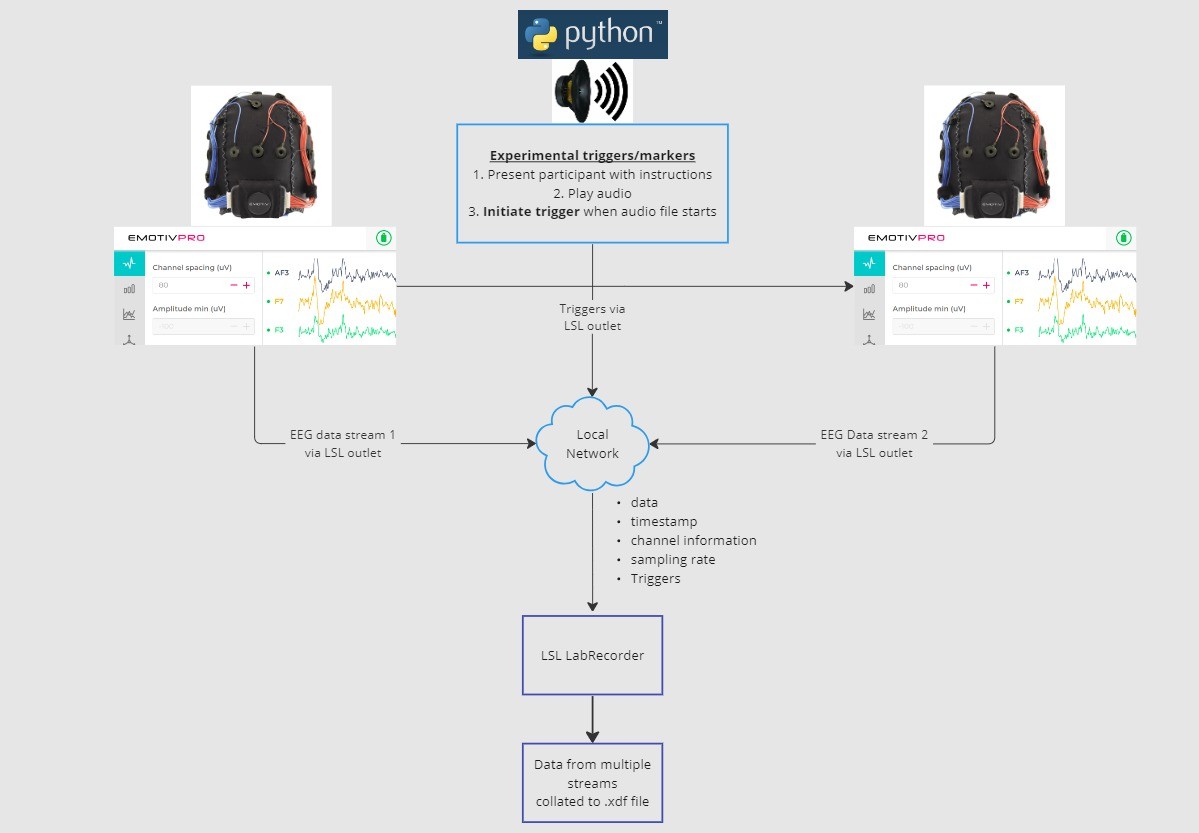
2.1 ÉTAPE 1 - Configuration et installation
Vous aurez besoin d'un appareils d'acquisition de données compatibles pour collecter les données
• Tous les appareils cérébraux d'Emotiv se connectent à LSL via le logiciel EmotivPROInstallez EmotivPRO sur votre ou vos appareils. Vous aurez besoin d'une licence EmotivPRO valide pour utiliser LSL.
Installez la bibliothèque Python LSL avec la commande suivante :
pip install pylslTéléchargez le logiciel LabRecorder. C'est une application simple et gratuite qui peut être exécutée depuis
la ligne de commande ou en utilisant un téléchargement autonomePour notre expérience : Installez les packages nécessaires pour lire de l'audio à l'aide de Python
pip install sounddevice soundfile
2.2 ÉTAPE 3 - Envoyer les données depuis EmotivPRO via un flux LSL
Repérez les « … » dans le coin supérieur droit de l'application, accédez aux Paramètres
Trouvez la section « Lab Streaming Layer » et la sous-section « Outlet »
Sélectionnez tous les types de données que vous souhaitez diffuser
Sélectionnez le format des données (flottant 32 bits ou double 64 bits)
Sélectionnez s'il faut envoyer les données échantillon par échantillon ou par paquets d'échantillons
Cliquez sur « Start » pour diffuser un flux de données LSL
2.3 ÉTAPE 4 - Utiliser un script Python pour lire de l’audio et envoyer des déclencheurs
Copiez et collez le bloc de code suivant dans un fichier python et enregistrez-le sur votre ordinateur.
Repérez un fichier audio (idéalement un fichier .wav) que vous souhaitez lire et modifiez le script en remplaçant la
variableaudio_filepathpar le chemin d'accès à votre fichier audio sur votre ordinateurOuvrez une invite de commande pour interagir avec la ligne de commande et accédez au dossier où
votre fichier Python est stockéSaisissez :
python3 filename.py
• Selon votre installation de Python, vous pouvez utiliserpythonau lieu depython3
Remarque : Remplacez/path/to/audio.wavpar l'emplacement du fichier audio que vous souhaitez lire pendant votre expérience.
""" Exemple LSL : Lire de l'audio et envoyer un marqueur de déclenchement <p>Ce script crée un flux de marqueurs LSL, attend que l'utilisateur<br>appuie sur ENTRÉE, puis lit un fichier audio et envoie un marqueur qui<br>peut être synchronisé avec les données EEG collectées via LabRecorder.<br>"""</p> <p>import sounddevice as sd<br>import soundfile as sf<br>from pylsl import StreamInfo, StreamOutlet</p> <p>def wait_for_keypress():<br>print("Appuyez sur ENTRÉE pour lancer la lecture audio et envoyer un marqueur LSL.")<br>while True:<br>if input() == "":<br>break</p> <p>def play_audio_and_send_marker(audio_file, outlet):<br>data, fs = sf.read(audio_file)</p> <pre><code>print("Lecture audio et envoi du marqueur LSL...") marker_val = [1] outlet.push_sample(marker_val) sd.play(data, fs) sd.wait() print("Lecture audio terminée.") </code></pre> <p>if <strong>name</strong> == "<strong>main</strong>":</p> <pre><code>info = StreamInfo( name="AudioMarkers", type="Markers", channel_count=1, nominal_srate=0, channel_format="int32", source_id="uniqueMarkerID12345" ) outlet = StreamOutlet(info) while True: wait_for_keypress() audio_filepath = "/path/to/audio.wav" play_audio_and_send_marker( audio_filepath, outlet )</code></pre><h2 dir="auto">2.4 ÉTAPE 5 - Utiliser LabRecorder pour visualiser et enregistrer tous les flux LSL</h2><ol dir="auto"><li data-preset-tag="p"><p>Ouvrez LabRecorder</p></li><li data-preset-tag="p"><p>Appuyez sur <code>Update</code>. Les flux LSL disponibles doivent être visibles dans la liste des flux<br>• Vous devriez pouvoir voir les flux des deux EmotivPRO (généralement appelés "Emotiv-<br>DataStream") et le flux de marqueurs (appelé "AudioMarkers")</p></li><li data-preset-tag="p"><p>Cliquez sur <code>Browse</code> pour sélectionner un emplacement pour stocker les données (et définir d'autres paramètres)</p></li><li data-preset-tag="p"><p>Sélectionnez tous les flux et appuyez sur <code>Record</code> pour commencer l'enregistrement</p></li></ol><h2 dir="auto">3.0 Travailler avec les données</h2><p dir="auto">LabRecorder génère un fichier XDF (Extensible Data Format) qui contient les données de tous les flux. Les fichiers XDF sont structurés en flux, chacun ayant un en-tête différent qui décrit ce qu'il contient (nom de l'appareil, type de données, fréquence d'échantillonnage, canaux, etc.). Vous pouvez utiliser le bloc de code ci-dessous pour ouvrir votre fichier XDF et afficher des informations de base.</p><p dir="auto"><strong>Remarque : Remplacez </strong><code><strong>/path/to/your/file.xdf</strong></code><strong> par le chemin d'accès de votre fichier de sortie LabRecorder XDF.</strong></p><pre data-language="JSX"><code>import pyxdf </code></pre> <p>import mne<br>import matplotlib.pyplot as plt<br>import numpy as np</p> <h1>Indiquez le chemin d'accès à votre fichier de sortie LSL ici.</h1> <p>data_path = "/path/to/your/file.xdf"</p> <h1>Chargez le fichier XDF.</h1> <p>streams, fileheader = pyxdf.load_xdf(data_path)</p> <p>print("En-tête du fichier XDF :", fileheader)<br>print("Nombre de flux trouvés :", len(streams))</p> <p>for i, stream in enumerate(streams):<br>print("\nFlux", i + 1)<br>print("Nom du flux :", stream["info"]["name"][0])<br>print("Type de flux :", stream["info"]["type"][0])<br>print("Nombre de canaux :", stream["info"]["channel_count"][0])</p> <pre><code>sfreq = float(stream["info"]["nominal_srate"][0]) print("Fréquence d'échantillonnage :", sfreq) print("Nombre d'échantillons :", len(stream["time_series"])) print("5 premiers points de données :", stream["time_series"][:5]) channel_names = [ chan["label"][0] for chan in stream["info"]["desc"][0]["channels"][0]["channel"] ] print("Noms des canaux :", channel_names) channel_types = "eeg"</code></pre><h3 dir="auto"><br></h3><h2 dir="auto">4.0 Ressources supplémentaires</h2><h4 dir="auto">Documentation officielle</h4><ol dir="auto"><li data-preset-tag="p"><p>Consultez la <a href="1. Check out the online documentation, including the official README file on GitHub 2. Additional resources: • Code to run LSL using Emotiv’s devices, with example scripts • Useful LSL demo on YouTube • SCCN LSL GitHub repository for all associated libraries • LSL GitHub repository for a collection a submodules and apps 3. HyPyP analysis pipeline for Hyperscanning studies" target="_blank">documentation en ligne</a>, y compris le <a href="https://github.com/sccn/labstreaminglayer/" target="_blank">fichier README officiel sur GitHub</a></p></li><li data-preset-tag="p"><p>Ressources supplémentaires :<br>• <a href="https://github.com/Emotiv/labstreaminglayer" target="_blank">Code</a> pour exécuter LSL à l'aide des appareils d'Emotiv, avec des exemples de scripts<br>• Utile <a href="https://www.youtube.com/watch?v=Y1at7yrcFW0&list=PLVnr33MP5RMRhGwY36zHHDOmAaYTB138D" target="_blank">démo LSL sur YouTube</a><br>• <a href="https://github.com/sccn/labstreaminglayer" target="_blank">Dépôt GitHub de SCCN LSL</a> pour toutes les bibliothèques associées<br>• <a href="https://github.com/labstreaminglayer" target="_blank">Dépôt GitHub de LSL</a> pour une collection de sous-modules et d'applications</p></li><li data-preset-tag="p"><p><a href="https://academic.oup.com/scan/article/16/1-2/72/5919711?login=false" target="_blank">Pipeline d'analyse HyPyP</a> pour les études d'hyperscan</p></li></ol> </code></pre>
""" Exemple LSL : Lire de l'audio et envoyer un marqueur de déclenchement <p>Ce script crée un flux de marqueurs LSL, attend que l'utilisateur<br>appuie sur ENTRÉE, puis lit un fichier audio et envoie un marqueur qui<br>peut être synchronisé avec les données EEG collectées via LabRecorder.<br>"""</p> <p>import sounddevice as sd<br>import soundfile as sf<br>from pylsl import StreamInfo, StreamOutlet</p> <p>def wait_for_keypress():<br>print("Appuyez sur ENTRÉE pour lancer la lecture audio et envoyer un marqueur LSL.")<br>while True:<br>if input() == "":<br>break</p> <p>def play_audio_and_send_marker(audio_file, outlet):<br>data, fs = sf.read(audio_file)</p> <pre><code>print("Lecture audio et envoi du marqueur LSL...") marker_val = [1] outlet.push_sample(marker_val) sd.play(data, fs) sd.wait() print("Lecture audio terminée.") </code></pre> <p>if <strong>name</strong> == "<strong>main</strong>":</p> <pre><code>info = StreamInfo( name="AudioMarkers", type="Markers", channel_count=1, nominal_srate=0, channel_format="int32", source_id="uniqueMarkerID12345" ) outlet = StreamOutlet(info) while True: wait_for_keypress() audio_filepath = "/path/to/audio.wav" play_audio_and_send_marker( audio_filepath, outlet )</code></pre><h2 dir="auto">2.4 ÉTAPE 5 - Utiliser LabRecorder pour visualiser et enregistrer tous les flux LSL</h2><ol dir="auto"><li data-preset-tag="p"><p>Ouvrez LabRecorder</p></li><li data-preset-tag="p"><p>Appuyez sur <code>Update</code>. Les flux LSL disponibles doivent être visibles dans la liste des flux<br>• Vous devriez pouvoir voir les flux des deux EmotivPRO (généralement appelés "Emotiv-<br>DataStream") et le flux de marqueurs (appelé "AudioMarkers")</p></li><li data-preset-tag="p"><p>Cliquez sur <code>Browse</code> pour sélectionner un emplacement pour stocker les données (et définir d'autres paramètres)</p></li><li data-preset-tag="p"><p>Sélectionnez tous les flux et appuyez sur <code>Record</code> pour commencer l'enregistrement</p></li></ol><h2 dir="auto">3.0 Travailler avec les données</h2><p dir="auto">LabRecorder génère un fichier XDF (Extensible Data Format) qui contient les données de tous les flux. Les fichiers XDF sont structurés en flux, chacun ayant un en-tête différent qui décrit ce qu'il contient (nom de l'appareil, type de données, fréquence d'échantillonnage, canaux, etc.). Vous pouvez utiliser le bloc de code ci-dessous pour ouvrir votre fichier XDF et afficher des informations de base.</p><p dir="auto"><strong>Remarque : Remplacez </strong><code><strong>/path/to/your/file.xdf</strong></code><strong> par le chemin d'accès de votre fichier de sortie LabRecorder XDF.</strong></p><pre data-language="JSX"><code>import pyxdf </code></pre> <p>import mne<br>import matplotlib.pyplot as plt<br>import numpy as np</p> <h1>Indiquez le chemin d'accès à votre fichier de sortie LSL ici.</h1> <p>data_path = "/path/to/your/file.xdf"</p> <h1>Chargez le fichier XDF.</h1> <p>streams, fileheader = pyxdf.load_xdf(data_path)</p> <p>print("En-tête du fichier XDF :", fileheader)<br>print("Nombre de flux trouvés :", len(streams))</p> <p>for i, stream in enumerate(streams):<br>print("\nFlux", i + 1)<br>print("Nom du flux :", stream["info"]["name"][0])<br>print("Type de flux :", stream["info"]["type"][0])<br>print("Nombre de canaux :", stream["info"]["channel_count"][0])</p> <pre><code>sfreq = float(stream["info"]["nominal_srate"][0]) print("Fréquence d'échantillonnage :", sfreq) print("Nombre d'échantillons :", len(stream["time_series"])) print("5 premiers points de données :", stream["time_series"][:5]) channel_names = [ chan["label"][0] for chan in stream["info"]["desc"][0]["channels"][0]["channel"] ] print("Noms des canaux :", channel_names) channel_types = "eeg"</code></pre><h3 dir="auto"><br></h3><h2 dir="auto">4.0 Ressources supplémentaires</h2><h4 dir="auto">Documentation officielle</h4><ol dir="auto"><li data-preset-tag="p"><p>Consultez la <a href="1. Check out the online documentation, including the official README file on GitHub 2. Additional resources: • Code to run LSL using Emotiv’s devices, with example scripts • Useful LSL demo on YouTube • SCCN LSL GitHub repository for all associated libraries • LSL GitHub repository for a collection a submodules and apps 3. HyPyP analysis pipeline for Hyperscanning studies" target="_blank">documentation en ligne</a>, y compris le <a href="https://github.com/sccn/labstreaminglayer/" target="_blank">fichier README officiel sur GitHub</a></p></li><li data-preset-tag="p"><p>Ressources supplémentaires :<br>• <a href="https://github.com/Emotiv/labstreaminglayer" target="_blank">Code</a> pour exécuter LSL à l'aide des appareils d'Emotiv, avec des exemples de scripts<br>• Utile <a href="https://www.youtube.com/watch?v=Y1at7yrcFW0&list=PLVnr33MP5RMRhGwY36zHHDOmAaYTB138D" target="_blank">démo LSL sur YouTube</a><br>• <a href="https://github.com/sccn/labstreaminglayer" target="_blank">Dépôt GitHub de SCCN LSL</a> pour toutes les bibliothèques associées<br>• <a href="https://github.com/labstreaminglayer" target="_blank">Dépôt GitHub de LSL</a> pour une collection de sous-modules et d'applications</p></li><li data-preset-tag="p"><p><a href="https://academic.oup.com/scan/article/16/1-2/72/5919711?login=false" target="_blank">Pipeline d'analyse HyPyP</a> pour les études d'hyperscan</p></li></ol> </code></pre>
""" Exemple LSL : Lire de l'audio et envoyer un marqueur de déclenchement <p>Ce script crée un flux de marqueurs LSL, attend que l'utilisateur<br>appuie sur ENTRÉE, puis lit un fichier audio et envoie un marqueur qui<br>peut être synchronisé avec les données EEG collectées via LabRecorder.<br>"""</p> <p>import sounddevice as sd<br>import soundfile as sf<br>from pylsl import StreamInfo, StreamOutlet</p> <p>def wait_for_keypress():<br>print("Appuyez sur ENTRÉE pour lancer la lecture audio et envoyer un marqueur LSL.")<br>while True:<br>if input() == "":<br>break</p> <p>def play_audio_and_send_marker(audio_file, outlet):<br>data, fs = sf.read(audio_file)</p> <pre><code>print("Lecture audio et envoi du marqueur LSL...") marker_val = [1] outlet.push_sample(marker_val) sd.play(data, fs) sd.wait() print("Lecture audio terminée.") </code></pre> <p>if <strong>name</strong> == "<strong>main</strong>":</p> <pre><code>info = StreamInfo( name="AudioMarkers", type="Markers", channel_count=1, nominal_srate=0, channel_format="int32", source_id="uniqueMarkerID12345" ) outlet = StreamOutlet(info) while True: wait_for_keypress() audio_filepath = "/path/to/audio.wav" play_audio_and_send_marker( audio_filepath, outlet )</code></pre><h2 dir="auto">2.4 ÉTAPE 5 - Utiliser LabRecorder pour visualiser et enregistrer tous les flux LSL</h2><ol dir="auto"><li data-preset-tag="p"><p>Ouvrez LabRecorder</p></li><li data-preset-tag="p"><p>Appuyez sur <code>Update</code>. Les flux LSL disponibles doivent être visibles dans la liste des flux<br>• Vous devriez pouvoir voir les flux des deux EmotivPRO (généralement appelés "Emotiv-<br>DataStream") et le flux de marqueurs (appelé "AudioMarkers")</p></li><li data-preset-tag="p"><p>Cliquez sur <code>Browse</code> pour sélectionner un emplacement pour stocker les données (et définir d'autres paramètres)</p></li><li data-preset-tag="p"><p>Sélectionnez tous les flux et appuyez sur <code>Record</code> pour commencer l'enregistrement</p></li></ol><h2 dir="auto">3.0 Travailler avec les données</h2><p dir="auto">LabRecorder génère un fichier XDF (Extensible Data Format) qui contient les données de tous les flux. Les fichiers XDF sont structurés en flux, chacun ayant un en-tête différent qui décrit ce qu'il contient (nom de l'appareil, type de données, fréquence d'échantillonnage, canaux, etc.). Vous pouvez utiliser le bloc de code ci-dessous pour ouvrir votre fichier XDF et afficher des informations de base.</p><p dir="auto"><strong>Remarque : Remplacez </strong><code><strong>/path/to/your/file.xdf</strong></code><strong> par le chemin d'accès de votre fichier de sortie LabRecorder XDF.</strong></p><pre data-language="JSX"><code>import pyxdf </code></pre> <p>import mne<br>import matplotlib.pyplot as plt<br>import numpy as np</p> <h1>Indiquez le chemin d'accès à votre fichier de sortie LSL ici.</h1> <p>data_path = "/path/to/your/file.xdf"</p> <h1>Chargez le fichier XDF.</h1> <p>streams, fileheader = pyxdf.load_xdf(data_path)</p> <p>print("En-tête du fichier XDF :", fileheader)<br>print("Nombre de flux trouvés :", len(streams))</p> <p>for i, stream in enumerate(streams):<br>print("\nFlux", i + 1)<br>print("Nom du flux :", stream["info"]["name"][0])<br>print("Type de flux :", stream["info"]["type"][0])<br>print("Nombre de canaux :", stream["info"]["channel_count"][0])</p> <pre><code>sfreq = float(stream["info"]["nominal_srate"][0]) print("Fréquence d'échantillonnage :", sfreq) print("Nombre d'échantillons :", len(stream["time_series"])) print("5 premiers points de données :", stream["time_series"][:5]) channel_names = [ chan["label"][0] for chan in stream["info"]["desc"][0]["channels"][0]["channel"] ] print("Noms des canaux :", channel_names) channel_types = "eeg"</code></pre><h3 dir="auto"><br></h3><h2 dir="auto">4.0 Ressources supplémentaires</h2><h4 dir="auto">Documentation officielle</h4><ol dir="auto"><li data-preset-tag="p"><p>Consultez la <a href="1. Check out the online documentation, including the official README file on GitHub 2. Additional resources: • Code to run LSL using Emotiv’s devices, with example scripts • Useful LSL demo on YouTube • SCCN LSL GitHub repository for all associated libraries • LSL GitHub repository for a collection a submodules and apps 3. HyPyP analysis pipeline for Hyperscanning studies" target="_blank">documentation en ligne</a>, y compris le <a href="https://github.com/sccn/labstreaminglayer/" target="_blank">fichier README officiel sur GitHub</a></p></li><li data-preset-tag="p"><p>Ressources supplémentaires :<br>• <a href="https://github.com/Emotiv/labstreaminglayer" target="_blank">Code</a> pour exécuter LSL à l'aide des appareils d'Emotiv, avec des exemples de scripts<br>• Utile <a href="https://www.youtube.com/watch?v=Y1at7yrcFW0&list=PLVnr33MP5RMRhGwY36zHHDOmAaYTB138D" target="_blank">démo LSL sur YouTube</a><br>• <a href="https://github.com/sccn/labstreaminglayer" target="_blank">Dépôt GitHub de SCCN LSL</a> pour toutes les bibliothèques associées<br>• <a href="https://github.com/labstreaminglayer" target="_blank">Dépôt GitHub de LSL</a> pour une collection de sous-modules et d'applications</p></li><li data-preset-tag="p"><p><a href="https://academic.oup.com/scan/article/16/1-2/72/5919711?login=false" target="_blank">Pipeline d'analyse HyPyP</a> pour les études d'hyperscan</p></li></ol> </code></pre>
Bienvenue ! Dans ce tutoriel, nous allons apprendre à utiliser Lab Streaming Layer (LSL) en Python pour collecter et synchroniser les données EEG d'Emotiv à partir de plusieurs appareils. Cela nécessitera des connaissances de base en langage de programmation Python.
Ce que vous allez apprendre
Ce qu'est Lab Streaming Layer (LSL) et pourquoi les chercheurs l'utilisent
Comment collecter des données synchronisées à partir de plusieurs appareils EEG d'Emotiv
Comment importer et inspecter les données collectées
1.1 Qu'est-ce que LSL et à quoi ça sert ?
Lab Streaming Layer (LSL) est une boîte à outils open-source qui peut être utilisée pour envoyer, recevoir et synchroniser des flux de données neuronales, physiologiques et comportementales provenant de divers matériels de capteurs. Des appareils de détection cérébrale et corporelle de plus en plus performants, précis et mobiles (comme les systèmes EEG d'Emotiv) amènent les neurosciences hors du laboratoire vers le monde des données en temps réel. Alors que les mesures cérébrales telles que l'EEG et la MEG étaient autrefois confinées aux laboratoires de recherche, les appareils mobiles nous permettent de collecter plusieurs données dans des environnements plus naturalistes, et de plusieurs personnes à la fois.
Un chercheur peut s'intéresser à la synchronie physiologique entre deux personnes écoutant la même musique. LSL peut nous aider à collecter séparément des données de deux casques EEG qui sont également synchronisées avec la présentation du son.
Quelques exemples d'autres utilisations de LSL :
Ajouter des marqueurs d'événements d'une expérience à des données EEG en cours
Aligner temporellement les données de sources multiples pour un seul participant (par exemple, fréquence cardiaque, EMG, EEG)
Aligner temporellement les données de plusieurs participants (par exemple, études d'hyperscan EEG)
1.2 Comment fonctionne LSL ?
Lab Streaming Layer est un protocole d'échange en temps réel de données de séries temporelles entre plusieurs appareils. LSL peut être implémenté à l'aide de bibliothèques open-source pour des langages de programmation tels que Python, MATLAB, C++, Java et autres.
La fonctionnalité principale tourne autour des flux de données LSL :
1. Un appareil/logiciel d'acquisition collecte les données et crée un flux de données - Les données physiologiques peuvent être transmises à LSL à partir d'appareils d'enregistrement EEG, d'oculomètres, de systèmes de capture de mouvement, de moniteurs de fréquence cardiaque, etc., y compris les métadonnées (taux d'échantillonnage, type de données, informations sur les canaux, etc.) - Les marqueurs d'événements issus d'expériences (par exemple, en utilisant PsychoPy) peuvent également être envoyés sous forme de flux de données à l'aide de LSL
2. Le flux de données est publié sur le réseau - C'est ainsi que les données sont envoyées à l'aide de LSL ; le flux de données est « diffusé » sur le réseau - Les flux publiés sont disponibles sur le réseau et détectables par d'autres appareils compatibles LSL sur le même réseau - LSL attribue à chaque bloc de données ou échantillon un horodatage basé sur une horloge commune (suivant le protocole Network Time Protocol). - Le flux est poussé échantillon par échantillon (ou bloc par bloc) à travers une « sortie » (outlet)
3. Les appareils de collecte s'« abonnent » aux flux de données - C'est ainsi que les données sont reçues à l'aide de LSL - Les appareils de collecte sur le même réseau reçoivent les flux de données publiés via des « entrées » (inlets). - Chaque entrée reçoit les échantillons de flux et les métadonnées d'une seule sortie
4. Sauvegarder les données - Lors de l'abonnement à un flux de données, vous pouvez le sauvegarder dans une variable de votre langage de programmation préféré, ou utiliser le logiciel fourni par LSL, LabRecorder, pour le sauvegarder dans un format standard tel que .xdf.
2.0 Aperçu du tutoriel
Dans ce tutoriel, nous prendrons un exemple d'installation expérimentale et vous guiderons à travers les étapes et le code nécessaires pour l'implémenter en utilisant LSL en Python. Nous utiliserons Python pour jouer un son tout en collectant des données EEG de deux personnes portant des casques Emotiv. Nous utiliserons deux ordinateurs exécutant chacun EmotivPRO pour collecter les données EEG, et diffuser chaque flux par une sortie LSL distincte. Nous utiliserons une bibliothèque Python pour lire un fichier audio et envoyer simultanément un déclencheur à chaque fois que le fichier démarre.
ÉTAPES :
1. Utiliser EmotivPRO pour diffuser des données via des sorties LSL qui incluent des données EEG (et/ou mouvement, qualité de contact, qualité du signal, etc.) 2. Lire une piste audio à l'aide d'un script Python, et envoyer simultanément un déclencheur via une autre sortie LSL. Utiliser LabRecorder pour capturer et sauvegarder les trois flux de données via une entrée LSL.
2.1 ÉTAPE 1 - Configuration et installation
Vous aurez besoin d'un appareils d'acquisition de données compatibles pour collecter les données
• Tous les appareils cérébraux d'Emotiv se connectent à LSL via le logiciel EmotivPROInstallez EmotivPRO sur votre ou vos appareils. Vous aurez besoin d'une licence EmotivPRO valide pour utiliser LSL.
Installez la bibliothèque Python LSL avec la commande suivante :
pip install pylslTéléchargez le logiciel LabRecorder. C'est une application simple et gratuite qui peut être exécutée depuis
la ligne de commande ou en utilisant un téléchargement autonomePour notre expérience : Installez les packages nécessaires pour lire de l'audio à l'aide de Python
pip install sounddevice soundfile
2.2 ÉTAPE 3 - Envoyer les données depuis EmotivPRO via un flux LSL
Repérez les « … » dans le coin supérieur droit de l'application, accédez aux Paramètres
Trouvez la section « Lab Streaming Layer » et la sous-section « Outlet »
Sélectionnez tous les types de données que vous souhaitez diffuser
Sélectionnez le format des données (flottant 32 bits ou double 64 bits)
Sélectionnez s'il faut envoyer les données échantillon par échantillon ou par paquets d'échantillons
Cliquez sur « Start » pour diffuser un flux de données LSL
2.3 ÉTAPE 4 - Utiliser un script Python pour lire de l’audio et envoyer des déclencheurs
Copiez et collez le bloc de code suivant dans un fichier python et enregistrez-le sur votre ordinateur.
Repérez un fichier audio (idéalement un fichier .wav) que vous souhaitez lire et modifiez le script en remplaçant la
variableaudio_filepathpar le chemin d'accès à votre fichier audio sur votre ordinateurOuvrez une invite de commande pour interagir avec la ligne de commande et accédez au dossier où
votre fichier Python est stockéSaisissez :
python3 filename.py
• Selon votre installation de Python, vous pouvez utiliserpythonau lieu depython3
Remarque : Remplacez/path/to/audio.wavpar l'emplacement du fichier audio que vous souhaitez lire pendant votre expérience.
""" Exemple LSL : Lire de l'audio et envoyer un marqueur de déclenchement <p>Ce script crée un flux de marqueurs LSL, attend que l'utilisateur<br>appuie sur ENTRÉE, puis lit un fichier audio et envoie un marqueur qui<br>peut être synchronisé avec les données EEG collectées via LabRecorder.<br>"""</p> <p>import sounddevice as sd<br>import soundfile as sf<br>from pylsl import StreamInfo, StreamOutlet</p> <p>def wait_for_keypress():<br>print("Appuyez sur ENTRÉE pour lancer la lecture audio et envoyer un marqueur LSL.")<br>while True:<br>if input() == "":<br>break</p> <p>def play_audio_and_send_marker(audio_file, outlet):<br>data, fs = sf.read(audio_file)</p> <pre><code>print("Lecture audio et envoi du marqueur LSL...") marker_val = [1] outlet.push_sample(marker_val) sd.play(data, fs) sd.wait() print("Lecture audio terminée.") </code></pre> <p>if <strong>name</strong> == "<strong>main</strong>":</p> <pre><code>info = StreamInfo( name="AudioMarkers", type="Markers", channel_count=1, nominal_srate=0, channel_format="int32", source_id="uniqueMarkerID12345" ) outlet = StreamOutlet(info) while True: wait_for_keypress() audio_filepath = "/path/to/audio.wav" play_audio_and_send_marker( audio_filepath, outlet )</code></pre><h2 dir="auto">2.4 ÉTAPE 5 - Utiliser LabRecorder pour visualiser et enregistrer tous les flux LSL</h2><ol dir="auto"><li data-preset-tag="p"><p>Ouvrez LabRecorder</p></li><li data-preset-tag="p"><p>Appuyez sur <code>Update</code>. Les flux LSL disponibles doivent être visibles dans la liste des flux<br>• Vous devriez pouvoir voir les flux des deux EmotivPRO (généralement appelés "Emotiv-<br>DataStream") et le flux de marqueurs (appelé "AudioMarkers")</p></li><li data-preset-tag="p"><p>Cliquez sur <code>Browse</code> pour sélectionner un emplacement pour stocker les données (et définir d'autres paramètres)</p></li><li data-preset-tag="p"><p>Sélectionnez tous les flux et appuyez sur <code>Record</code> pour commencer l'enregistrement</p></li></ol><h2 dir="auto">3.0 Travailler avec les données</h2><p dir="auto">LabRecorder génère un fichier XDF (Extensible Data Format) qui contient les données de tous les flux. Les fichiers XDF sont structurés en flux, chacun ayant un en-tête différent qui décrit ce qu'il contient (nom de l'appareil, type de données, fréquence d'échantillonnage, canaux, etc.). Vous pouvez utiliser le bloc de code ci-dessous pour ouvrir votre fichier XDF et afficher des informations de base.</p><p dir="auto"><strong>Remarque : Remplacez </strong><code><strong>/path/to/your/file.xdf</strong></code><strong> par le chemin d'accès de votre fichier de sortie LabRecorder XDF.</strong></p><pre data-language="JSX"><code>import pyxdf </code></pre> <p>import mne<br>import matplotlib.pyplot as plt<br>import numpy as np</p> <h1>Indiquez le chemin d'accès à votre fichier de sortie LSL ici.</h1> <p>data_path = "/path/to/your/file.xdf"</p> <h1>Chargez le fichier XDF.</h1> <p>streams, fileheader = pyxdf.load_xdf(data_path)</p> <p>print("En-tête du fichier XDF :", fileheader)<br>print("Nombre de flux trouvés :", len(streams))</p> <p>for i, stream in enumerate(streams):<br>print("\nFlux", i + 1)<br>print("Nom du flux :", stream["info"]["name"][0])<br>print("Type de flux :", stream["info"]["type"][0])<br>print("Nombre de canaux :", stream["info"]["channel_count"][0])</p> <pre><code>sfreq = float(stream["info"]["nominal_srate"][0]) print("Fréquence d'échantillonnage :", sfreq) print("Nombre d'échantillons :", len(stream["time_series"])) print("5 premiers points de données :", stream["time_series"][:5]) channel_names = [ chan["label"][0] for chan in stream["info"]["desc"][0]["channels"][0]["channel"] ] print("Noms des canaux :", channel_names) channel_types = "eeg"</code></pre><h3 dir="auto"><br></h3><h2 dir="auto">4.0 Ressources supplémentaires</h2><h4 dir="auto">Documentation officielle</h4><ol dir="auto"><li data-preset-tag="p"><p>Consultez la <a href="1. Check out the online documentation, including the official README file on GitHub 2. Additional resources: • Code to run LSL using Emotiv’s devices, with example scripts • Useful LSL demo on YouTube • SCCN LSL GitHub repository for all associated libraries • LSL GitHub repository for a collection a submodules and apps 3. HyPyP analysis pipeline for Hyperscanning studies" target="_blank">documentation en ligne</a>, y compris le <a href="https://github.com/sccn/labstreaminglayer/" target="_blank">fichier README officiel sur GitHub</a></p></li><li data-preset-tag="p"><p>Ressources supplémentaires :<br>• <a href="https://github.com/Emotiv/labstreaminglayer" target="_blank">Code</a> pour exécuter LSL à l'aide des appareils d'Emotiv, avec des exemples de scripts<br>• Utile <a href="https://www.youtube.com/watch?v=Y1at7yrcFW0&list=PLVnr33MP5RMRhGwY36zHHDOmAaYTB138D" target="_blank">démo LSL sur YouTube</a><br>• <a href="https://github.com/sccn/labstreaminglayer" target="_blank">Dépôt GitHub de SCCN LSL</a> pour toutes les bibliothèques associées<br>• <a href="https://github.com/labstreaminglayer" target="_blank">Dépôt GitHub de LSL</a> pour une collection de sous-modules et d'applications</p></li><li data-preset-tag="p"><p><a href="https://academic.oup.com/scan/article/16/1-2/72/5919711?login=false" target="_blank">Pipeline d'analyse HyPyP</a> pour les études d'hyperscan</p></li></ol> </code></pre>
Bienvenue ! Dans ce tutoriel, nous allons apprendre à utiliser Lab Streaming Layer (LSL) en Python pour collecter et synchroniser les données EEG d'Emotiv à partir de plusieurs appareils. Cela nécessitera des connaissances de base en langage de programmation Python.
Ce que vous allez apprendre
Ce qu'est Lab Streaming Layer (LSL) et pourquoi les chercheurs l'utilisent
Comment collecter des données synchronisées à partir de plusieurs appareils EEG d'Emotiv
Comment importer et inspecter les données collectées
1.1 Qu'est-ce que LSL et à quoi ça sert ?
Lab Streaming Layer (LSL) est une boîte à outils open-source qui peut être utilisée pour envoyer, recevoir et synchroniser des flux de données neuronales, physiologiques et comportementales provenant de divers matériels de capteurs. Des appareils de détection cérébrale et corporelle de plus en plus performants, précis et mobiles (comme les systèmes EEG d'Emotiv) amènent les neurosciences hors du laboratoire vers le monde des données en temps réel. Alors que les mesures cérébrales telles que l'EEG et la MEG étaient autrefois confinées aux laboratoires de recherche, les appareils mobiles nous permettent de collecter plusieurs données dans des environnements plus naturalistes, et de plusieurs personnes à la fois.
Un chercheur peut s'intéresser à la synchronie physiologique entre deux personnes écoutant la même musique. LSL peut nous aider à collecter séparément des données de deux casques EEG qui sont également synchronisées avec la présentation du son.
Quelques exemples d'autres utilisations de LSL :
Ajouter des marqueurs d'événements d'une expérience à des données EEG en cours
Aligner temporellement les données de sources multiples pour un seul participant (par exemple, fréquence cardiaque, EMG, EEG)
Aligner temporellement les données de plusieurs participants (par exemple, études d'hyperscan EEG)
1.2 Comment fonctionne LSL ?
Lab Streaming Layer est un protocole d'échange en temps réel de données de séries temporelles entre plusieurs appareils. LSL peut être implémenté à l'aide de bibliothèques open-source pour des langages de programmation tels que Python, MATLAB, C++, Java et autres.
La fonctionnalité principale tourne autour des flux de données LSL :
1. Un appareil/logiciel d'acquisition collecte les données et crée un flux de données - Les données physiologiques peuvent être transmises à LSL à partir d'appareils d'enregistrement EEG, d'oculomètres, de systèmes de capture de mouvement, de moniteurs de fréquence cardiaque, etc., y compris les métadonnées (taux d'échantillonnage, type de données, informations sur les canaux, etc.) - Les marqueurs d'événements issus d'expériences (par exemple, en utilisant PsychoPy) peuvent également être envoyés sous forme de flux de données à l'aide de LSL
2. Le flux de données est publié sur le réseau - C'est ainsi que les données sont envoyées à l'aide de LSL ; le flux de données est « diffusé » sur le réseau - Les flux publiés sont disponibles sur le réseau et détectables par d'autres appareils compatibles LSL sur le même réseau - LSL attribue à chaque bloc de données ou échantillon un horodatage basé sur une horloge commune (suivant le protocole Network Time Protocol). - Le flux est poussé échantillon par échantillon (ou bloc par bloc) à travers une « sortie » (outlet)
3. Les appareils de collecte s'« abonnent » aux flux de données - C'est ainsi que les données sont reçues à l'aide de LSL - Les appareils de collecte sur le même réseau reçoivent les flux de données publiés via des « entrées » (inlets). - Chaque entrée reçoit les échantillons de flux et les métadonnées d'une seule sortie
4. Sauvegarder les données - Lors de l'abonnement à un flux de données, vous pouvez le sauvegarder dans une variable de votre langage de programmation préféré, ou utiliser le logiciel fourni par LSL, LabRecorder, pour le sauvegarder dans un format standard tel que .xdf.
2.0 Aperçu du tutoriel
Dans ce tutoriel, nous prendrons un exemple d'installation expérimentale et vous guiderons à travers les étapes et le code nécessaires pour l'implémenter en utilisant LSL en Python. Nous utiliserons Python pour jouer un son tout en collectant des données EEG de deux personnes portant des casques Emotiv. Nous utiliserons deux ordinateurs exécutant chacun EmotivPRO pour collecter les données EEG, et diffuser chaque flux par une sortie LSL distincte. Nous utiliserons une bibliothèque Python pour lire un fichier audio et envoyer simultanément un déclencheur à chaque fois que le fichier démarre.
ÉTAPES :
1. Utiliser EmotivPRO pour diffuser des données via des sorties LSL qui incluent des données EEG (et/ou mouvement, qualité de contact, qualité du signal, etc.) 2. Lire une piste audio à l'aide d'un script Python, et envoyer simultanément un déclencheur via une autre sortie LSL. Utiliser LabRecorder pour capturer et sauvegarder les trois flux de données via une entrée LSL.
2.1 ÉTAPE 1 - Configuration et installation
Vous aurez besoin d'un appareils d'acquisition de données compatibles pour collecter les données
• Tous les appareils cérébraux d'Emotiv se connectent à LSL via le logiciel EmotivPROInstallez EmotivPRO sur votre ou vos appareils. Vous aurez besoin d'une licence EmotivPRO valide pour utiliser LSL.
Installez la bibliothèque Python LSL avec la commande suivante :
pip install pylslTéléchargez le logiciel LabRecorder. C'est une application simple et gratuite qui peut être exécutée depuis
la ligne de commande ou en utilisant un téléchargement autonomePour notre expérience : Installez les packages nécessaires pour lire de l'audio à l'aide de Python
pip install sounddevice soundfile
2.2 ÉTAPE 3 - Envoyer les données depuis EmotivPRO via un flux LSL
Repérez les « … » dans le coin supérieur droit de l'application, accédez aux Paramètres
Trouvez la section « Lab Streaming Layer » et la sous-section « Outlet »
Sélectionnez tous les types de données que vous souhaitez diffuser
Sélectionnez le format des données (flottant 32 bits ou double 64 bits)
Sélectionnez s'il faut envoyer les données échantillon par échantillon ou par paquets d'échantillons
Cliquez sur « Start » pour diffuser un flux de données LSL
2.3 ÉTAPE 4 - Utiliser un script Python pour lire de l’audio et envoyer des déclencheurs
Copiez et collez le bloc de code suivant dans un fichier python et enregistrez-le sur votre ordinateur.
Repérez un fichier audio (idéalement un fichier .wav) que vous souhaitez lire et modifiez le script en remplaçant la
variableaudio_filepathpar le chemin d'accès à votre fichier audio sur votre ordinateurOuvrez une invite de commande pour interagir avec la ligne de commande et accédez au dossier où
votre fichier Python est stockéSaisissez :
python3 filename.py
• Selon votre installation de Python, vous pouvez utiliserpythonau lieu depython3
Remarque : Remplacez/path/to/audio.wavpar l'emplacement du fichier audio que vous souhaitez lire pendant votre expérience.
""" Exemple LSL : Lire de l'audio et envoyer un marqueur de déclenchement <p>Ce script crée un flux de marqueurs LSL, attend que l'utilisateur<br>appuie sur ENTRÉE, puis lit un fichier audio et envoie un marqueur qui<br>peut être synchronisé avec les données EEG collectées via LabRecorder.<br>"""</p> <p>import sounddevice as sd<br>import soundfile as sf<br>from pylsl import StreamInfo, StreamOutlet</p> <p>def wait_for_keypress():<br>print("Appuyez sur ENTRÉE pour lancer la lecture audio et envoyer un marqueur LSL.")<br>while True:<br>if input() == "":<br>break</p> <p>def play_audio_and_send_marker(audio_file, outlet):<br>data, fs = sf.read(audio_file)</p> <pre><code>print("Lecture audio et envoi du marqueur LSL...") marker_val = [1] outlet.push_sample(marker_val) sd.play(data, fs) sd.wait() print("Lecture audio terminée.") </code></pre> <p>if <strong>name</strong> == "<strong>main</strong>":</p> <pre><code>info = StreamInfo( name="AudioMarkers", type="Markers", channel_count=1, nominal_srate=0, channel_format="int32", source_id="uniqueMarkerID12345" ) outlet = StreamOutlet(info) while True: wait_for_keypress() audio_filepath = "/path/to/audio.wav" play_audio_and_send_marker( audio_filepath, outlet )</code></pre><h2 dir="auto">2.4 ÉTAPE 5 - Utiliser LabRecorder pour visualiser et enregistrer tous les flux LSL</h2><ol dir="auto"><li data-preset-tag="p"><p>Ouvrez LabRecorder</p></li><li data-preset-tag="p"><p>Appuyez sur <code>Update</code>. Les flux LSL disponibles doivent être visibles dans la liste des flux<br>• Vous devriez pouvoir voir les flux des deux EmotivPRO (généralement appelés "Emotiv-<br>DataStream") et le flux de marqueurs (appelé "AudioMarkers")</p></li><li data-preset-tag="p"><p>Cliquez sur <code>Browse</code> pour sélectionner un emplacement pour stocker les données (et définir d'autres paramètres)</p></li><li data-preset-tag="p"><p>Sélectionnez tous les flux et appuyez sur <code>Record</code> pour commencer l'enregistrement</p></li></ol><h2 dir="auto">3.0 Travailler avec les données</h2><p dir="auto">LabRecorder génère un fichier XDF (Extensible Data Format) qui contient les données de tous les flux. Les fichiers XDF sont structurés en flux, chacun ayant un en-tête différent qui décrit ce qu'il contient (nom de l'appareil, type de données, fréquence d'échantillonnage, canaux, etc.). Vous pouvez utiliser le bloc de code ci-dessous pour ouvrir votre fichier XDF et afficher des informations de base.</p><p dir="auto"><strong>Remarque : Remplacez </strong><code><strong>/path/to/your/file.xdf</strong></code><strong> par le chemin d'accès de votre fichier de sortie LabRecorder XDF.</strong></p><pre data-language="JSX"><code>import pyxdf </code></pre> <p>import mne<br>import matplotlib.pyplot as plt<br>import numpy as np</p> <h1>Indiquez le chemin d'accès à votre fichier de sortie LSL ici.</h1> <p>data_path = "/path/to/your/file.xdf"</p> <h1>Chargez le fichier XDF.</h1> <p>streams, fileheader = pyxdf.load_xdf(data_path)</p> <p>print("En-tête du fichier XDF :", fileheader)<br>print("Nombre de flux trouvés :", len(streams))</p> <p>for i, stream in enumerate(streams):<br>print("\nFlux", i + 1)<br>print("Nom du flux :", stream["info"]["name"][0])<br>print("Type de flux :", stream["info"]["type"][0])<br>print("Nombre de canaux :", stream["info"]["channel_count"][0])</p> <pre><code>sfreq = float(stream["info"]["nominal_srate"][0]) print("Fréquence d'échantillonnage :", sfreq) print("Nombre d'échantillons :", len(stream["time_series"])) print("5 premiers points de données :", stream["time_series"][:5]) channel_names = [ chan["label"][0] for chan in stream["info"]["desc"][0]["channels"][0]["channel"] ] print("Noms des canaux :", channel_names) channel_types = "eeg"</code></pre><h3 dir="auto"><br></h3><h2 dir="auto">4.0 Ressources supplémentaires</h2><h4 dir="auto">Documentation officielle</h4><ol dir="auto"><li data-preset-tag="p"><p>Consultez la <a href="1. Check out the online documentation, including the official README file on GitHub 2. Additional resources: • Code to run LSL using Emotiv’s devices, with example scripts • Useful LSL demo on YouTube • SCCN LSL GitHub repository for all associated libraries • LSL GitHub repository for a collection a submodules and apps 3. HyPyP analysis pipeline for Hyperscanning studies" target="_blank">documentation en ligne</a>, y compris le <a href="https://github.com/sccn/labstreaminglayer/" target="_blank">fichier README officiel sur GitHub</a></p></li><li data-preset-tag="p"><p>Ressources supplémentaires :<br>• <a href="https://github.com/Emotiv/labstreaminglayer" target="_blank">Code</a> pour exécuter LSL à l'aide des appareils d'Emotiv, avec des exemples de scripts<br>• Utile <a href="https://www.youtube.com/watch?v=Y1at7yrcFW0&list=PLVnr33MP5RMRhGwY36zHHDOmAaYTB138D" target="_blank">démo LSL sur YouTube</a><br>• <a href="https://github.com/sccn/labstreaminglayer" target="_blank">Dépôt GitHub de SCCN LSL</a> pour toutes les bibliothèques associées<br>• <a href="https://github.com/labstreaminglayer" target="_blank">Dépôt GitHub de LSL</a> pour une collection de sous-modules et d'applications</p></li><li data-preset-tag="p"><p><a href="https://academic.oup.com/scan/article/16/1-2/72/5919711?login=false" target="_blank">Pipeline d'analyse HyPyP</a> pour les études d'hyperscan</p></li></ol> </code></pre>
Continuez à lire